結論
pythonには、lru_cacheと呼ばれる標準機能があります。
個人的に、納得できる解説がなかったので、ここにまとめます。
結論、下記のようにまとめられます。
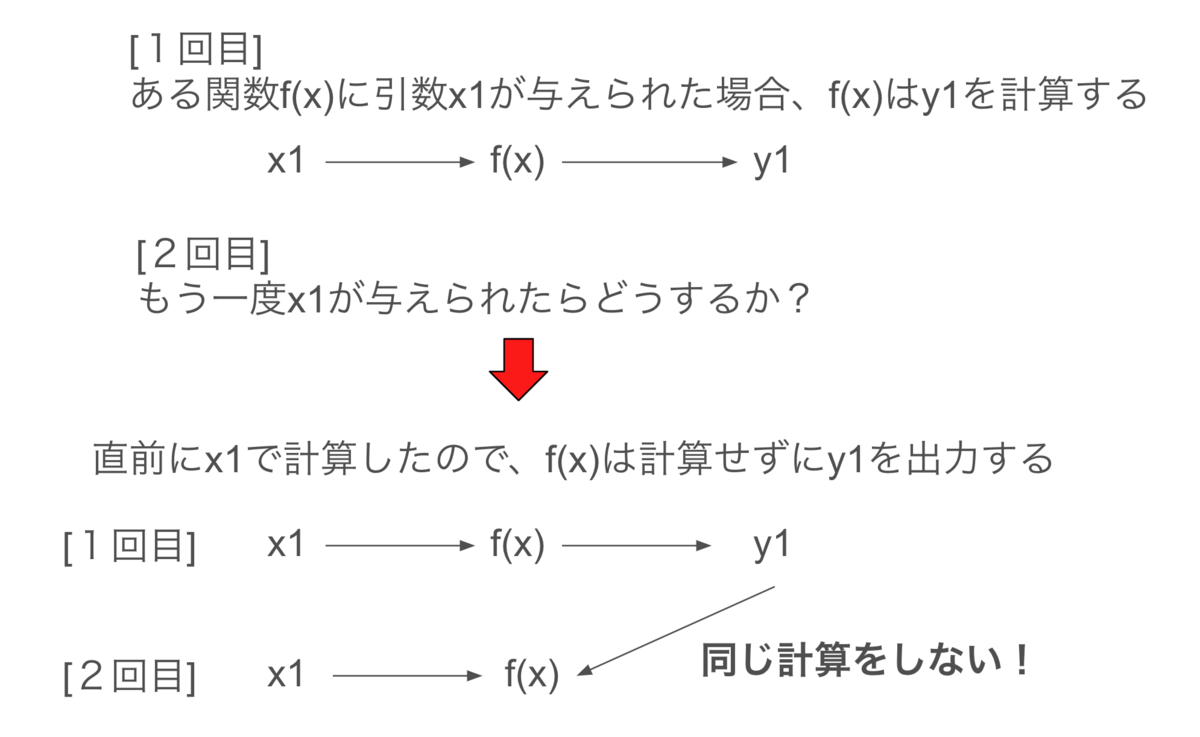
言葉で説明すると、
メソッドのある引数に対する計算結果を保存しておき、後で同じ引数が与えられた時、計算結果を再利用するというものである。
となります。
では、具体例を見ていきましょう。
具体例
そもそも、lru_cacheは、
from functools import lru_cache
のように使用します。
以下、サンプルコードを考えてみましょう。
from functools import lru_cache import time @lru_cache def my_func(x): time.sleep(3) return x # 1回目 s = time.time() my_func(1000) print(time.time() - s) # 2回目 s = time.time() my_func(1000) print(time.time() - s)
my_func関数にlru_cacheがついています。
この実行結果を見てみると、、、
3.004951000213623 2.1457672119140625e-06
となります。
これは、
my_func関数に対して、一回目でx=1000で計算しています。そのため、2回目で、同じ関数を呼び出すとき、同じ引数が使われているため、3秒待たずにレスポンスが返されます。
使い方のイメージ
個人的に想像しえる使い方のイメージです。
- オブジェクトクラスを立てる関数
→ インスタンスを立てる処理自体は、使い回しが聞くので。
- ネットワークリクエストを返す関数
-> 2回目からは同じリクエストであれば、計算時間が向上するので。
- 引数に計算元となるPATHを指定して、特定の計算をする関数
-> 入ってくるデータが同じであれば、計算結果も同じになるので。
以上になります。
皆様の理解の一助になれば幸いです。
コメントもらえると勇気が湧きます!よろしくお願いします!